Redux Essentials,第 7 部分:RTK Query 基础
- RTK Query 如何简化 Redux 应用的数据获取
- 如何设置 RTK Query
- 如何使用 RTK Query 进行基本数据获取和更新请求
- 完成本教程的先前部分以了解 Redux Toolkit 的使用模式
如果您想看视频课程,您可以 在 Egghead 免费观看由 RTK Query 创建者 Lenz Weber-Tronic 制作的 RTK Query 视频课程,或者直接观看第一课
简介
在 第 5 部分:异步逻辑和数据获取 和 第 6 部分:性能和规范化 中,我们看到了在 Redux 中用于数据获取和缓存的标准模式。这些模式包括使用异步 thunk 获取数据,使用结果分发操作,在存储中管理请求加载状态,以及规范化缓存数据以更轻松地按 ID 查找和更新单个项目。
在本节中,我们将了解如何使用 RTK Query,这是一个专为 Redux 应用程序设计的用于数据获取和缓存的解决方案,并了解它如何简化数据获取和在组件中使用数据的过程。
RTK Query 概述
RTK Query 是一款功能强大的数据获取和缓存工具。它旨在简化 Web 应用程序中加载数据的常见情况,无需手动编写数据获取和缓存逻辑。
RTK Query 是 Redux Toolkit 包中可选的附加组件,其功能建立在 Redux Toolkit 中其他 API 的基础之上。
动机
Web 应用程序通常需要从服务器获取数据以显示。它们通常还需要更新这些数据,将这些更新发送到服务器,并将客户端上的缓存数据与服务器上的数据保持同步。由于需要实现当今应用程序中使用的其他行为,这变得更加复杂。
- 跟踪加载状态以显示 UI 旋转器
- 避免对相同数据的重复请求
- 乐观更新以使 UI 感觉更快
- 管理缓存生命周期,因为用户与 UI 交互
我们已经看到如何使用 Redux Toolkit 实现这些行为。
但是,从历史上看,Redux 从未包含任何内置的东西来帮助完全解决这些用例。即使我们将createAsyncThunk与createSlice一起使用,在进行请求和管理加载状态方面仍然需要相当多的手动工作。我们必须创建异步 thunk,发出实际请求,从响应中提取相关字段,添加加载状态字段,在extraReducers中添加处理程序以处理pending/fulfilled/rejected情况,并实际编写正确的状态更新。
在过去几年中,React 社区已经意识到“数据获取和缓存”实际上与“状态管理”是不同的关注点。虽然可以使用 Redux 等状态管理库来缓存数据,但用例足够不同,因此值得使用专门针对数据获取用例的工具。
RTK Query 从其他为数据获取开创解决方案的工具(如 Apollo Client、React Query、Urql 和 SWR)中汲取灵感,但对其 API 设计采用了独特的方法。
- 数据获取和缓存逻辑建立在 Redux Toolkit 的
createSlice和createAsyncThunkAPI 之上。 - 由于 Redux Toolkit 与 UI 无关,因此 RTK Query 的功能可以与任何 UI 层一起使用。
- API 端点在提前定义,包括如何从参数生成查询参数以及如何转换响应以进行缓存。
- RTK Query 还可以生成 React hooks,这些 hooks 封装了整个数据获取过程,为组件提供
data和isFetching字段,并在组件挂载和卸载时管理缓存数据的生命周期。 - RTK Query 提供了“缓存条目生命周期”选项,这些选项支持诸如在获取初始数据后通过 websocket 消息流式传输缓存更新之类的用例。
- 我们拥有从 OpenAPI 和 GraphQL 模式生成 API 片段的早期工作示例。
- 最后,RTK Query 完全用 TypeScript 编写,旨在提供出色的 TS 使用体验。
包含的内容
API
RTK Query 包含在核心 Redux Toolkit 包的安装中。它可以通过以下两个入口点中的任何一个使用。
import { createApi } from '@reduxjs/toolkit/query'
/* React-specific entry point that automatically generates
hooks corresponding to the defined endpoints */
import { createApi } from '@reduxjs/toolkit/query/react'
RTK Query 主要包含两个 API。
createApi(): RTK Query 功能的核心。它允许您定义一组端点,描述如何从一系列端点检索数据,包括如何获取和转换该数据的配置。在大多数情况下,您应该在每个应用程序中使用一次,以“每个基本 URL 一个 API 片段”为经验法则。fetchBaseQuery(): 一个围绕fetch的小型包装器,旨在简化请求。旨在作为大多数用户在createApi中使用的推荐baseQuery。
包大小
RTK Query 会向您的应用程序包大小添加一个固定的单次数量。由于 RTK Query 建立在 Redux Toolkit 和 React-Redux 之上,因此添加的大小会根据您是否已经在应用程序中使用它们而有所不同。估计的 min+gzip 包大小为
- 如果您已经在使用 RTK:RTK Query 大约 9kb,hooks 大约 2kb。
- 如果您尚未使用 RTK
- 没有 React:RTK+依赖项+RTK Query 为 17 kB
- 使用 React:19kB + React-Redux,它是对等依赖项
添加额外的端点定义应该只会根据endpoints定义中实际代码的大小增加大小,这通常只有几个字节。
RTK Query 中包含的功能很快就能弥补增加的包大小,并且消除手动编写的數據获取逻辑对于大多数有意义的应用程序来说应该是包大小的净改进。
RTK Query 缓存中的思考
Redux 一直以来都强调可预测性和明确的行为。Redux 中没有“魔法”——你应该能够理解应用程序中发生的事情,因为所有 Redux 逻辑都遵循相同的调度操作和通过 reducer 更新状态的基本模式。这意味着有时你必须编写更多代码才能使事情发生,但权衡是应该非常清楚数据流和行为是什么。
Redux Toolkit 核心 API 不会改变 Redux 应用程序中的任何基本数据流你仍然在调度操作和编写 reducer,只是比手动编写所有这些逻辑要少写代码。RTK Query 也是如此。它是一个额外的抽象层,但在内部它仍然执行我们已经看到用于管理异步请求及其响应的完全相同的步骤。
但是,当你使用 RTK Query 时,确实会发生一种思维方式的转变。我们不再考虑“管理状态”本身。相反,我们现在考虑“管理缓存数据”。与其尝试自己编写 reducer,我们现在将专注于定义“这些数据来自哪里?”,“如何发送此更新?”,“何时应该重新获取此缓存数据?”,以及“如何更新缓存数据?”。这些数据如何被获取、存储和检索成为我们不再需要担心的实现细节。
我们将看到这种思维方式的转变是如何随着我们的继续而应用的。
设置 RTK Query
我们的示例应用程序已经可以工作,但现在是时候将所有异步逻辑迁移到使用 RTK Query。在进行的过程中,我们将看到如何使用 RTK Query 的所有主要功能,以及如何将现有createAsyncThunk和createSlice的使用迁移到使用 RTK Query API。
定义 API 切片
之前,我们为每种不同的数据类型(如帖子、用户和通知)定义了单独的“切片”。每个切片都有自己的 reducer,定义了自己的操作和 thunk,并分别缓存了该数据类型的条目。
使用 RTK Query,管理缓存数据的逻辑集中在每个应用程序的单个“API 切片”中。就像你每个应用程序只有一个 Redux store 一样,我们现在有一个切片用于所有我们的缓存数据。
首先,我们将定义一个新的 apiSlice.js 文件。由于它不属于我们之前编写的任何其他“功能”,我们将添加一个新的 features/api/ 文件夹并将 apiSlice.js 放入其中。让我们填写 API 切片文件,然后分解其中的代码以了解它的作用。
// Import the RTK Query methods from the React-specific entry point
import { createApi, fetchBaseQuery } from '@reduxjs/toolkit/query/react'
// Define our single API slice object
export const apiSlice = createApi({
// The cache reducer expects to be added at `state.api` (already default - this is optional)
reducerPath: 'api',
// All of our requests will have URLs starting with '/fakeApi'
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
// The "endpoints" represent operations and requests for this server
endpoints: builder => ({
// The `getPosts` endpoint is a "query" operation that returns data
getPosts: builder.query({
// The URL for the request is '/fakeApi/posts'
query: () => '/posts'
})
})
})
// Export the auto-generated hook for the `getPosts` query endpoint
export const { useGetPostsQuery } = apiSlice
RTK Query 的功能基于一个名为 createApi 的方法。我们迄今为止看到的所有 Redux Toolkit API 都是与 UI 无关的,可以与任何 UI 层一起使用。RTK Query 的核心逻辑也是如此。但是,RTK Query 还包含 createApi 的 React 特定版本,由于我们将 RTK 和 React 结合使用,因此我们需要使用它来利用 RTK 的 React 集成。因此,我们从 '@reduxjs/toolkit/query/react' 中导入。
您的应用程序预计只包含一个 createApi 调用。这个 API 切片应该包含所有与同一个基本 URL 通信的端点定义。例如,端点 /api/posts 和 /api/users 都从同一个服务器获取数据,因此它们应该放在同一个 API 切片中。如果您的应用程序确实从多个服务器获取数据,您可以为每个端点指定完整 URL,或者在必要时为每个服务器创建单独的 API 切片。
端点通常直接在 createApi 调用中定义。如果您想将端点拆分到多个文件中,请参阅文档第 8 部分的“注入端点”部分!
API 切片参数
当我们调用 createApi 时,有两个字段是必需的
baseQuery:一个知道如何从服务器获取数据的函数。RTK Query 包含fetchBaseQuery,它是标准fetch()函数的一个小包装器,它处理请求和响应的典型处理。当我们创建一个fetchBaseQuery实例时,我们可以传入所有未来请求的基本 URL,以及覆盖行为,例如修改请求头。endpoints:我们为与该服务器交互而定义的一组操作。端点可以是查询,它返回用于缓存的数据,或者变异,它向服务器发送更新。端点是使用接受builder参数并返回包含使用builder.query()和builder.mutation()创建的端点定义的对象的回调函数定义的。
createApi 还接受一个 reducerPath 字段,它定义了为生成的 reducer 预期的顶级状态切片字段。对于我们其他像 postsSlice 这样的切片,没有保证它将用于更新 state.posts - 我们可以将 reducer 附加到根状态中的任何位置,例如 someOtherField: postsReducer。在这里,createApi 期望我们告诉它,当我们将缓存 reducer 添加到存储时,缓存状态将存在于哪里。如果您没有提供 reducerPath 选项,它将默认为 'api',因此您所有 RTKQ 缓存数据都将存储在 state.api 下。
如果你忘记将 reducer 添加到 store 中,或者将其附加到与 reducerPath 中指定的键不同的键上,RTKQ 会记录错误,以告知你需要修复此问题。
定义端点
所有请求的 URL 的第一部分在 fetchBaseQuery 定义中定义为 '/fakeApi'。
作为第一步,我们要添加一个端点,它将返回来自模拟 API 服务器的完整帖子列表。我们将包含一个名为 getPosts 的端点,并使用 builder.query() 将其定义为一个 **查询端点**。此方法接受许多选项,用于配置如何发出请求和处理响应。现在,我们只需要通过定义一个 query 选项来提供 URL 路径的剩余部分,该选项带有一个返回 URL 字符串的回调:() => '/posts'。
默认情况下,查询端点将使用 GET HTTP 请求,但你可以通过返回类似 {url: '/posts', method: 'POST', body: newPost} 的对象来覆盖它,而不是只返回 URL 字符串本身。你还可以通过这种方式为请求定义其他几个选项,例如设置标头。
导出 API 切片和钩子
在我们之前的切片文件中,我们只导出了操作创建者和切片 reducer,因为这些是其他文件中所需的一切。使用 RTK Query,我们通常会导出整个“API 切片”对象本身,因为它具有几个可能很有用的字段。
最后,仔细看看这个文件的最后一行。这个 useGetPostsQuery 值从哪里来?
RTK Query 的 React 集成将自动为我们定义的每个端点生成 React 钩子! 这些钩子封装了在组件挂载时触发请求的过程,并在请求处理和数据可用时重新渲染组件。我们可以将这些钩子从这个 API 切片文件导出,以便在我们的 React 组件中使用。
这些钩子根据标准约定自动命名
use,任何 React 钩子的正常前缀- 端点的名称,首字母大写
- 端点的类型,
Query或Mutation
在本例中,我们的端点是 getPosts,它是一个查询端点,因此生成的钩子是 useGetPostsQuery。
配置存储
现在我们需要将 API 切片连接到我们的 Redux 存储。我们可以修改现有的 store.js 文件,将 API 切片的缓存 reducer 添加到状态中。此外,API 切片会生成一个自定义中间件,需要将其添加到存储中。这个中间件必须添加 - 它管理缓存生命周期和过期。
import postsReducer from '../features/posts/postsSlice'
import usersReducer from '../features/users/usersSlice'
import notificationsReducer from '../features/notifications/notificationsSlice'
import { apiSlice } from '../features/api/apiSlice'
export default configureStore({
reducer: {
posts: postsReducer,
users: usersReducer,
notifications: notificationsReducer,
[apiSlice.reducerPath]: apiSlice.reducer
},
middleware: getDefaultMiddleware =>
getDefaultMiddleware().concat(apiSlice.middleware)
})
我们可以将 apiSlice.reducerPath 字段作为 reducer 参数中的计算键重用,以确保缓存 reducer 添加到正确的位置。
我们需要在存储设置中保留所有现有的标准中间件,例如 redux-thunk,并且 API 切片的中间件通常位于这些中间件之后。我们可以通过向 configureStore 提供 middleware 参数,调用提供的 getDefaultMiddleware() 方法,并将 apiSlice.middleware 添加到返回的中间件数组的末尾来实现这一点。
使用查询显示帖子
在组件中使用查询钩子
现在我们已经定义了 API 切片并将其添加到存储中,我们可以将生成的 useGetPostsQuery 钩子导入到我们的 <PostsList> 组件中并在那里使用它。
目前,<PostsList> 特别地导入了 useSelector、useDispatch 和 useEffect,从存储中读取帖子数据和加载状态,并在挂载时分派 fetchPosts() thunk 以触发数据获取。useGetPostsQueryHook 替换了所有这些!
让我们看看当我们使用这个钩子时 <PostsList> 是什么样子
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { PostAuthor } from './PostAuthor'
import { TimeAgo } from './TimeAgo'
import { ReactionButtons } from './ReactionButtons'
import { useGetPostsQuery } from '../api/apiSlice'
let PostExcerpt = ({ post }) => {
return (
<article className="post-excerpt" key={post.id}>
<h3>{post.title}</h3>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content.substring(0, 100)}</p>
<ReactionButtons post={post} />
<Link to={`/posts/${post.id}`} className="button muted-button">
View Post
</Link>
</article>
)
}
export const PostsList = () => {
const {
data: posts,
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = posts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
从概念上讲,<PostsList> 仍然在做之前的所有工作,但是我们能够用对 useGetPostsQuery() 的单次调用替换多个 useSelector 调用和 useEffect 分派。
你通常应该使用查询钩子来访问组件中的缓存数据 - 你不应该编写自己的 useSelector 调用来访问获取的数据或 useEffect 调用来触发获取!
每个生成的查询钩子都会返回一个包含多个字段的“result”对象,包括
data:来自服务器的实际响应内容。此字段在收到响应之前将为undefined。isLoading:一个布尔值,指示此钩子当前是否正在向服务器发出第一个请求。(注意,如果参数更改以请求不同的数据,isLoading将保持为 false。)isFetching:一个布尔值,指示此钩子当前是否正在向服务器发出任何请求isSuccess:一个布尔值,指示此钩子是否已成功发出请求并已缓存可用数据(即,data现在应该已定义)isError:一个布尔值,指示上次请求是否发生错误error:一个序列化错误对象
通常会从 result 对象中解构字段,并可能将 data 重命名为更具体的变量,例如 posts 来描述它包含的内容。然后,我们可以使用状态布尔值和 data/error 字段来渲染我们想要的 UI。但是,如果您使用的是 TypeScript,您可能需要保留原始对象,并在条件检查中将标志引用为 result.isSuccess,以便 TS 可以正确推断 data 是否有效。
以前,我们从 store 中选择一个帖子 ID 列表,将帖子 ID 传递给每个 <PostExcerpt> 组件,并分别从 store 中选择每个单独的 Post 对象。由于 posts 数组已经包含所有帖子对象,因此我们已切换回将帖子对象本身作为 props 传递。
排序帖子
不幸的是,帖子现在按错误的顺序显示。以前,我们使用 createEntityAdapter 的排序选项在 reducer 级别按日期对它们进行排序。由于 API 切片只是缓存从服务器返回的精确数组,因此没有进行特定的排序 - 服务器返回的任何顺序都是我们得到的。
有几种不同的方法可以处理这个问题。现在,我们将在 <PostsList> 本身内进行排序,我们将在以后讨论其他选项及其权衡。
我们不能直接调用 `posts.sort()`,因为 `Array.sort()` 会修改现有数组,所以我们需要先复制一份。为了避免在每次重新渲染时都重新排序,我们可以在 `useMemo()` 钩子中进行排序。我们还需要给 `posts` 设置一个默认的空数组,以防它为 `undefined`,这样我们始终都有一个数组可以排序。
// omit setup
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isSuccess,
isError,
error
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
// Sort posts in descending chronological order
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = sortedPosts.map(post => <PostExcerpt key={post.id} post={post} />)
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
{content}
</section>
)
}
显示单个帖子
我们已经更新了 `<PostsList>` 来获取所有帖子的列表,并且我们在列表中显示了每个 `Post` 的片段。但是,如果我们点击任何一个帖子的“查看帖子”,我们的 `<SinglePostPage>` 组件将无法在旧的 `state.posts` 切片中找到帖子,并显示“帖子未找到!”错误。我们需要更新 `<SinglePostPage>` 以使用 RTK Query。
我们可以用几种方法来实现。一种方法是让 `<SinglePostPage>` 调用相同的 `useGetPostsQuery()` 钩子,获取所有帖子的数组,然后找到它需要显示的唯一 `Post` 对象。查询钩子还具有 `selectFromResult` 选项,它允许我们在钩子本身内部更早地进行相同的查找 - 我们将在后面看到它的实际应用。
相反,我们将尝试添加另一个端点定义,它允许我们根据帖子的 ID 从服务器请求单个帖子。这有点多余,但它将让我们看到如何使用 RTK Query 根据参数自定义查询请求。
添加单个帖子查询端点
在 `apiSlice.js` 中,我们将添加另一个查询端点定义,名为 `getPost`(这次没有 's')
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts'
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
})
})
})
export const { useGetPostsQuery, useGetPostQuery } = apiSlice
`getPost` 端点看起来很像现有的 `getPosts` 端点,但 `query` 参数不同。在这里,`query` 接受一个名为 `postId` 的参数,我们使用该 `postId` 来构建服务器 URL。这样,我们可以对单个特定的 `Post` 对象进行服务器请求。
这也生成一个新的 `useGetPostQuery` 钩子,所以我们也导出它。
查询参数和缓存键
我们的 `<SinglePostPage>` 目前正在根据 ID 从 `state.posts` 中读取一个 `Post` 条目。我们需要更新它以调用新的 `useGetPostQuery` 钩子,并使用与主列表类似的加载状态。
import React from 'react'
import { Link } from 'react-router-dom'
import { Spinner } from '../../components/Spinner'
import { useGetPostQuery } from '../api/apiSlice'
import { PostAuthor } from './PostAuthor'
import { TimeAgo } from './TimeAgo'
import { ReactionButtons } from './ReactionButtons'
export const SinglePostPage = ({ match }) => {
const { postId } = match.params
const { data: post, isFetching, isSuccess } = useGetPostQuery(postId)
let content
if (isFetching) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
content = (
<article className="post">
<h2>{post.title}</h2>
<div>
<PostAuthor userId={post.user} />
<TimeAgo timestamp={post.date} />
</div>
<p className="post-content">{post.content}</p>
<ReactionButtons post={post} />
<Link to={`/editPost/${post.id}`} className="button">
Edit Post
</Link>
</article>
)
}
return <section>{content}</section>
}
请注意,我们正在获取从路由匹配中读取的 `postId`,并将其作为参数传递给 `useGetPostQuery`。然后,查询钩子将使用它来构建请求 URL,并获取此特定 `Post` 对象。
那么,所有这些数据是如何被缓存的呢?让我们点击一个帖子的“查看帖子”,然后看看此时 Redux 存储中的内容。
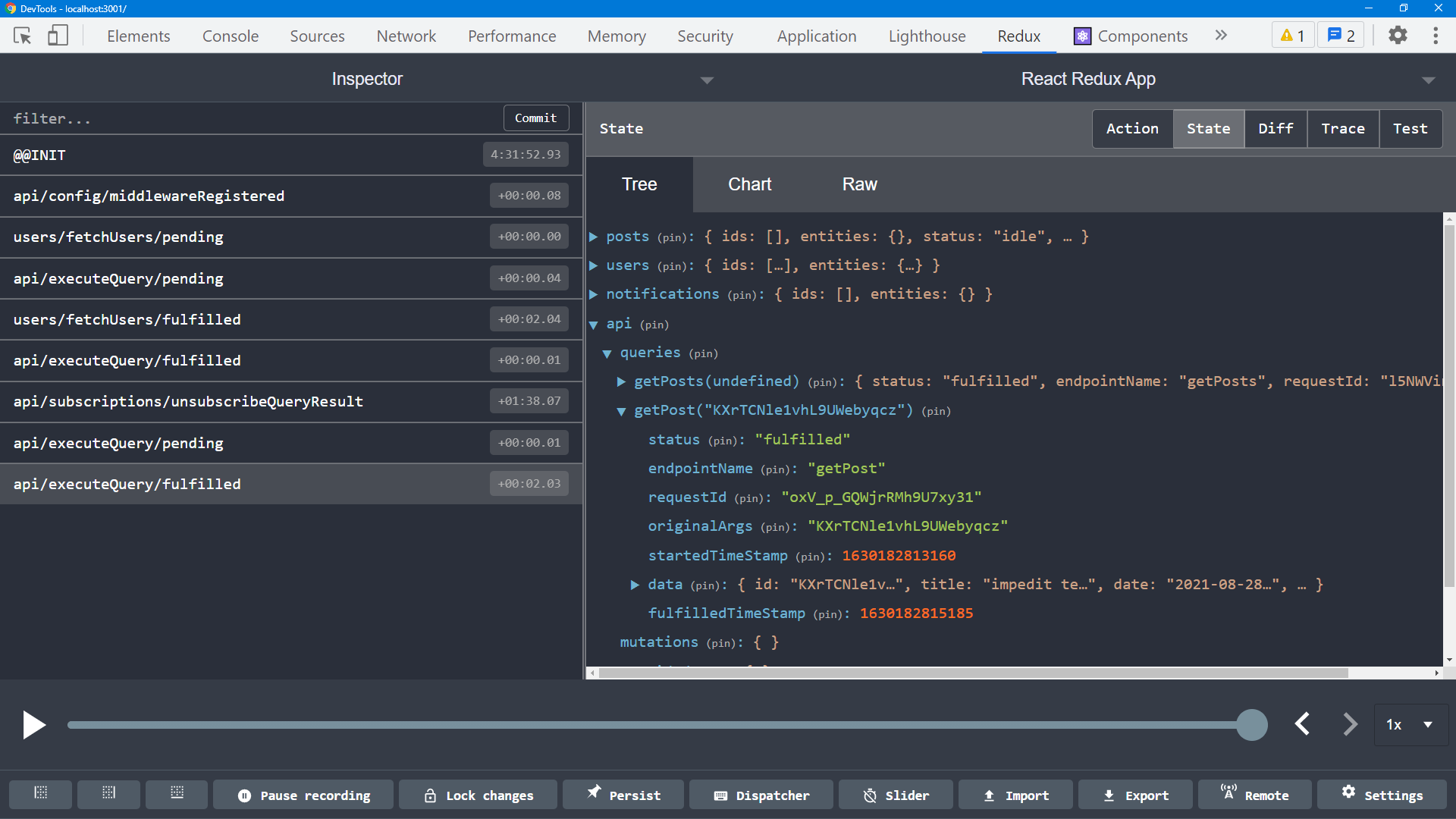
我们可以看到,我们有一个顶层的 `state.api` 切片,正如存储设置中所预期的那样。在里面有一个名为 `queries` 的部分,它目前有两个项目。键 `getPosts(undefined)` 代表我们使用 `getPosts` 端点发出的请求的元数据和响应内容。类似地,键 `getPost('abcd1234')` 用于我们刚刚对这个特定帖子发出的请求。
RTK Query 为每个唯一的端点 + 参数组合创建一个“缓存键”,并分别存储每个缓存键的结果。这意味着 **您可以多次使用相同的查询钩子,传递不同的查询参数,并且每个结果都将分别缓存在 Redux 存储中**。
如果多个组件需要相同的数据,只需在每个组件中使用相同的查询钩子并传入相同的参数!例如,您可以在三个不同的组件中调用 useGetPostQuery('123'),RTK Query 会确保数据只被获取一次,并且每个组件都会根据需要重新渲染。
同样重要的是要注意,**查询参数必须是单个值!** 如果您需要传递多个参数,则必须传递一个包含多个字段的对象(与 createAsyncThunk 完全相同)。RTK Query 将对这些字段进行“浅层稳定”比较,如果任何字段发生变化,则会重新获取数据。
请注意,左侧列表中操作的名称更通用,描述性更弱:api/executeQuery/fulfilled,而不是 posts/fetchPosts/fulfilled。这是使用额外抽象层的一种权衡。单个操作确实包含 action.meta.arg.endpointName 下的特定端点名称,但在操作历史列表中并不容易查看。
Redux DevTools 具有一个“RTK Query”选项卡,专门以更易用的格式显示 RTK Query 数据。这包括有关每个端点和缓存结果的信息、查询计时统计信息等等。
使用 Mutation 创建帖子
我们已经了解了如何通过定义“查询”端点从服务器获取数据,但如何向服务器发送更新呢?
RTK Query 允许我们定义**mutation 端点**,用于更新服务器上的数据。让我们添加一个 mutation,让我们添加一个新的帖子。
添加新的帖子 Mutation 端点
添加 mutation 端点与添加查询端点非常相似。最大的区别是我们使用 builder.mutation() 而不是 builder.query() 来定义端点。此外,我们现在需要将 HTTP 方法更改为 'POST' 请求,并且我们还必须提供请求主体。
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts'
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
// Include the entire post object as the body of the request
body: initialPost
})
})
})
})
export const {
useGetPostsQuery,
useGetPostQuery,
useAddNewPostMutation
} = apiSlice
这里我们的 query 选项返回一个包含 {url, method, body} 的对象。由于我们使用 fetchBaseQuery 来发出请求,因此 body 字段将自动为我们进行 JSON 序列化。
与查询端点类似,API 切片会自动为变异端点生成一个 React 钩子 - 在这种情况下,为 useAddNewPostMutation。
在组件中使用变异钩子
我们的 <AddPostForm> 已经派发了异步 thunk,以便在每次我们点击“保存帖子”按钮时添加帖子。为此,它必须导入 useDispatch 和 addNewPost thunk。变异钩子替换了这两个,并且使用模式非常相似。
import React, { useState } from 'react'
import { useSelector } from 'react-redux'
import { Spinner } from '../../components/Spinner'
import { useAddNewPostMutation } from '../api/apiSlice'
import { selectAllUsers } from '../users/usersSlice'
export const AddPostForm = () => {
const [title, setTitle] = useState('')
const [content, setContent] = useState('')
const [userId, setUserId] = useState('')
const [addNewPost, { isLoading }] = useAddNewPostMutation()
const users = useSelector(selectAllUsers)
const onTitleChanged = e => setTitle(e.target.value)
const onContentChanged = e => setContent(e.target.value)
const onAuthorChanged = e => setUserId(e.target.value)
const canSave = [title, content, userId].every(Boolean) && !isLoading
const onSavePostClicked = async () => {
if (canSave) {
try {
await addNewPost({ title, content, user: userId }).unwrap()
setTitle('')
setContent('')
setUserId('')
} catch (err) {
console.error('Failed to save the post: ', err)
}
}
}
// omit rendering logic
}
变异钩子返回一个包含两个值的数组
- 第一个值是“触发函数”。当被调用时,它会向服务器发出请求,并附带你提供的任何参数。这实际上就像一个已经包装好的 thunk,可以立即自行派发。
- 第二个值是一个对象,包含有关当前正在进行的请求(如果有)的元数据。这包括一个
isLoading标志,用于指示请求是否正在进行。
我们可以用 useAddNewPostMutation 钩子中的触发函数和 isLoading 标志替换现有的 thunk 派发和组件加载状态,组件的其余部分保持不变。
与 thunk 派发一样,我们用初始帖子对象调用 addNewPost。这将返回一个带有 .unwrap() 方法的特殊 Promise,我们可以使用 await addNewPost().unwrap() 来处理标准 try/catch 块中的任何潜在错误。
刷新缓存数据
当我们点击“保存帖子”时,我们可以查看浏览器 DevTools 中的网络选项卡,并确认 HTTP POST 请求已成功。但是,如果我们返回 <PostsList>,新帖子不会显示出来。我们仍然在内存中拥有相同的缓存数据。
我们需要告诉 RTK Query 刷新其缓存的帖子列表,以便我们可以看到我们刚刚添加的新帖子。
手动重新获取帖子
第一个选项是手动强制 RTK Query 重新获取给定端点的数据。查询钩子结果对象包含一个 refetch 函数,我们可以调用它来强制重新获取。我们可以暂时在 <PostsList> 中添加一个“重新获取帖子”按钮,并在添加新帖子后点击它。
此外,我们之前看到查询钩子既有 isLoading 标志(如果这是对数据的第一次请求,则为 true),也有 isFetching 标志(如果任何对数据的请求正在进行中,则为 true)。我们可以查看 isFetching 标志,并在重新获取正在进行时,再次用加载动画替换整个帖子列表。但是,这可能有点烦人,而且,我们已经拥有了所有这些帖子,为什么要完全隐藏它们呢?
相反,我们可以使现有的帖子列表部分透明,以表明数据已过期,但在重新获取发生时保持可见。一旦请求完成,我们就可以恢复正常显示帖子列表。
import React, { useMemo } from 'react'
import { Link } from 'react-router-dom'
import classnames from 'classnames'
// omit other imports and PostExcerpt
export const PostsList = () => {
const {
data: posts = [],
isLoading,
isFetching,
isSuccess,
isError,
error,
refetch
} = useGetPostsQuery()
const sortedPosts = useMemo(() => {
const sortedPosts = posts.slice()
sortedPosts.sort((a, b) => b.date.localeCompare(a.date))
return sortedPosts
}, [posts])
let content
if (isLoading) {
content = <Spinner text="Loading..." />
} else if (isSuccess) {
const renderedPosts = sortedPosts.map(post => (
<PostExcerpt key={post.id} post={post} />
))
const containerClassname = classnames('posts-container', {
disabled: isFetching
})
content = <div className={containerClassname}>{renderedPosts}</div>
} else if (isError) {
content = <div>{error.toString()}</div>
}
return (
<section className="posts-list">
<h2>Posts</h2>
<button onClick={refetch}>Refetch Posts</button>
{content}
</section>
)
}
如果我们添加一个新帖子,然后点击“重新获取帖子”,我们现在应该看到帖子列表在几秒钟内变为半透明,然后重新渲染,并将新添加的帖子添加到顶部。
使用缓存失效自动刷新
让用户手动点击重新获取数据偶尔是必要的,但绝对不是正常使用的好方法。
我们知道我们的“服务器”拥有所有帖子的完整列表,包括我们刚刚添加的帖子。理想情况下,我们希望在突变请求完成后,让我们的应用程序自动重新获取更新的帖子列表。这样我们就知道我们的客户端缓存数据与服务器上的数据同步。
RTK Query 允许我们定义查询和突变之间的关系,以使用“标签”启用自动数据重新获取。“标签”是一个字符串或小型对象,它允许您命名某些类型的数据,并使缓存的某些部分失效。当缓存标签失效时,RTK Query 将自动重新获取标记了该标签的端点。
基本标签使用需要在我们的 API 切片中添加三部分信息
- API 切片对象中的根
tagTypes字段,声明数据类型(如'Post')的字符串标签名称数组 - 查询端点中的
providesTags数组,列出描述该查询中数据的标签集 - 突变端点中的
invalidatesTags数组,列出每次突变运行时失效的标签集
我们可以向我们的 API 切片添加一个名为 'Post' 的单个标签,它将允许我们每次添加新帖子时自动重新获取 getPosts 端点
export const apiSlice = createApi({
reducerPath: 'api',
baseQuery: fetchBaseQuery({ baseUrl: '/fakeApi' }),
tagTypes: ['Post'],
endpoints: builder => ({
getPosts: builder.query({
query: () => '/posts',
providesTags: ['Post']
}),
getPost: builder.query({
query: postId => `/posts/${postId}`
}),
addNewPost: builder.mutation({
query: initialPost => ({
url: '/posts',
method: 'POST',
body: initialPost
}),
invalidatesTags: ['Post']
})
})
})
这就是我们所需要的!现在,如果我们点击“保存帖子”,您应该看到 <PostsList> 组件在几秒钟后自动变灰,然后重新渲染,并将新添加的帖子添加到顶部。
请注意,这里 'Post' 这个字面量字符串并没有什么特别之处。我们可以将其命名为 'Fred'、'qwerty' 或其他任何名称。它只需要在每个字段中保持一致,这样 RTK Query 才能知道“当发生此突变时,使所有带有相同标签字符串的端点失效”。
你学到了什么
使用 RTK Query,管理数据获取、缓存和加载状态的实际细节被抽象化了。这大大简化了应用程序代码,让我们可以专注于更高层次的应用程序行为目标。由于 RTK Query 是使用我们已经见过的相同 Redux Toolkit API 实现的,我们仍然可以使用 Redux DevTools 查看随着时间的推移状态的变化。
- RTK Query 是 Redux Toolkit 中包含的一个数据获取和缓存解决方案。
- RTK Query 为您抽象了管理缓存的服务器数据的过程,并消除了编写加载状态逻辑、存储结果和发出请求的必要性。
- RTK Query 基于 Redux 中使用的相同模式构建,例如异步 thunk。
- RTK Query 每个应用程序使用一个“API 切片”,使用
createApi定义。- RTK Query 提供了与 UI 无关的和特定于 React 的
createApi版本。 - API 切片为不同的服务器操作定义了多个“端点”。
- 如果使用 React 集成,API 切片将包含自动生成的 React 钩子。
- RTK Query 提供了与 UI 无关的和特定于 React 的
- 查询端点允许从服务器获取和缓存数据。
- 查询钩子返回一个
data值,以及加载状态标志。 - 查询可以手动重新获取,也可以使用“标签”自动获取以进行缓存失效。
- 查询钩子返回一个
- 突变端点允许更新服务器上的数据。
- 突变钩子返回一个“触发”函数,该函数发送更新请求,以及加载状态。
- 触发函数返回一个 Promise,可以“解包”并等待。
下一步
RTK Query 提供了可靠的默认行为,但也包含许多选项,用于自定义请求管理和缓存数据的操作方式。在 第 8 部分:RTK Query 高级模式 中,我们将了解如何使用这些选项来实现诸如乐观更新之类的有用功能。